使用 TinaCMS 与 Next.js
Tina + Next: 第二部分
这篇博客是探索使用 Next.js + Tina 系列的一部分。在第一部分中,您学习了如何使用 Next 创建一个简单的基于 Markdown 的博客。在这篇文章中,您将通过配置 TinaCMS 为网站添加内容编辑功能。
Next.js 回顾 ▲
Next.js 是一个由 Vercel 团队构建的用于开发 Web 应用程序的 React “元框架”(一个基于框架构建的框架)。阅读第一部分以熟悉 Next.js 的基础知识。
Tina 概述 🦙
Tina 是一个基于 Git 的无头内容管理系统,使开发人员和内容创作者能够无缝协作。使用 Tina,开发人员可以创建一个完全适合其网站的自定义可视化编辑体验。
体验 Tina 的最佳方式是使用它。我们希望通过本教程,您不仅能学会如何使用 Tina,还能了解 Tina 如何重新思考 CMS 的工作方式。
让我们开始吧
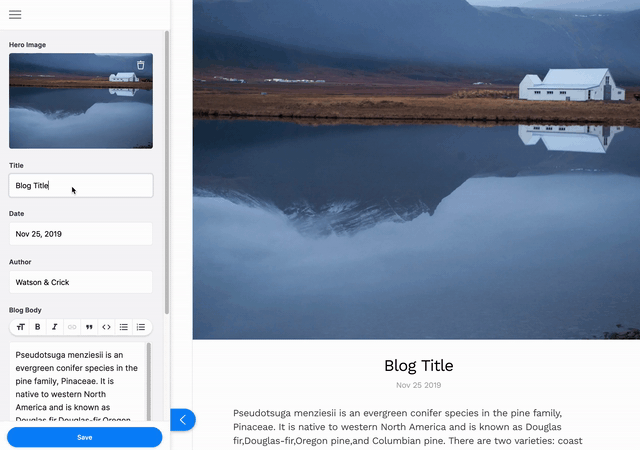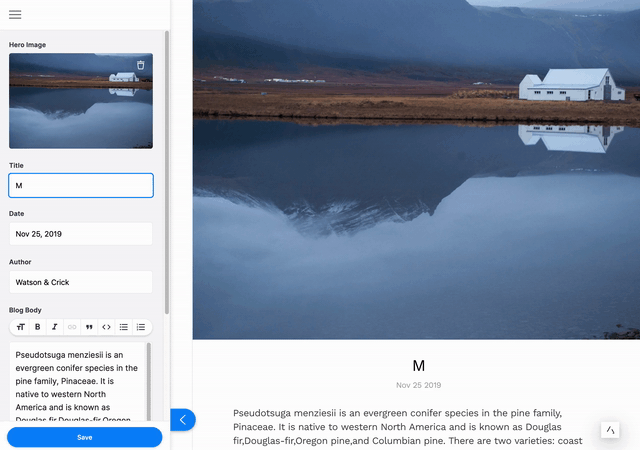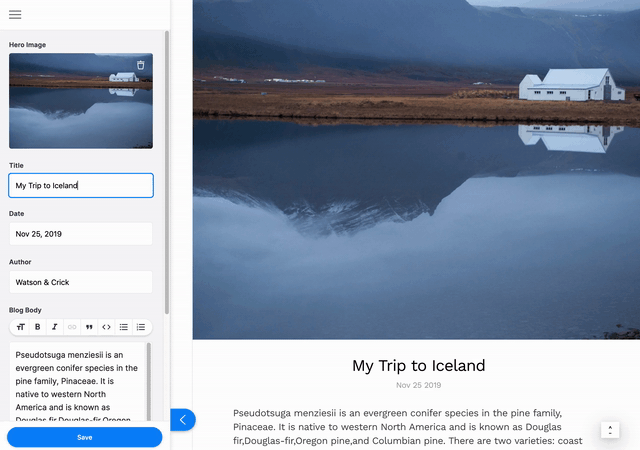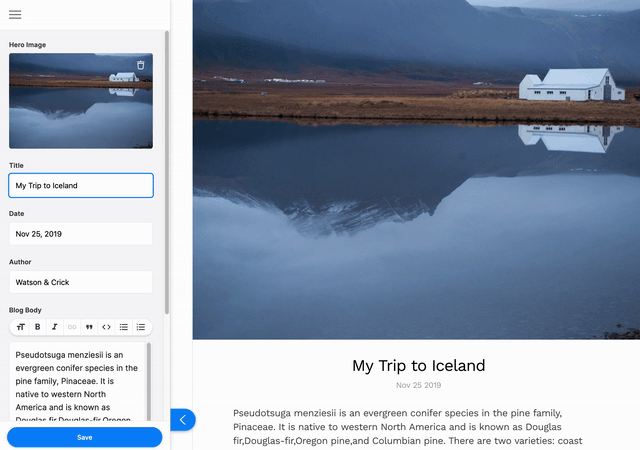
本教程将向您展示如何安装和配置 Tina 以编辑上周文章中创建的简单基于 Markdown 的博客。如果您想深入了解基础博客的制作过程,请阅读本系列的第一部分。
跳到这里查看 Tina 文档
本地设置 🏡
请随意按照这些指南将其适配到您自己的网站或博客,或者您可以使用我们在上一个教程中创建的入门模板。在终端中,导航到您希望博客所在的位置,然后运行:
# 克隆仓库$ git clone https://github.com/tinalabs/brevifolia-next-2022 next-tina-blog# 导航到目录$ cd next-tina-blog# 安装依赖 & 初始化 Tina$ yarn install$ npx @tinacms/cli@latest init$ 您希望我们覆盖您的 _app.js 吗?是
npx @tinacms/cli@latest init 命令在您的 Next.js 应用程序中执行以下操作:
- 安装 Tina 所需的所有依赖
- 在 .tina 目录中定义一个易于扩展的基本架构
- 使用 Tina 包装您的 next.js 应用程序,以便任何页面都可以轻松编辑
- 在 demo 目录中创建示例内容
- 编辑 package.json 以添加启动 tina 的脚本(dev、build、start)
快速测试
现在您有了一个基本的 Tina 设置,您可以使用以下命令启动您的应用程序:
yarn dev
启动应用程序后,您将有几个新的 URL:
http://localhost:3000/demo/blog/HelloWorldhttp://localhost:4001/altair/
第一个 URL 将带您到 TinaCMS 的演示,它将向您展示 Tina 的强大功能,并提供一些信息链接供您查看。如果您导航到 http://localhost:3000/demo/blog/HelloWorld,您将无法立即编辑。首先,您需要进入编辑模式。要进入编辑模式,请导航到 http://localhost:3000/admin,选择登录。然后返回到 http://localhost:3000/demo/blog/HelloWorld。选择左上角的铅笔可以直接在前端编辑页面的标题和正文。当您点击保存时,您的更改将保存到 Markdown 文件中。
想查看您的更改吗?打开位于/content/posts/HelloWorld.md的文件,您所做的更改将会在那里!这通过我们的内容 API 实现,我们将在本指南中更深入地探讨。
第二个 URL http://localhost:4001/altair/ 将启动一个 graphQL 客户端,允许您在本指南中进行交互和创建查询。
定义我们的内容结构
Tina 的一个关键元素是定义一个架构,允许您塑造和与页面上的内容进行交互。打开项目,您将看到一个名为 .tina 的文件夹,其中包含一个 schema.ts 文件。此文件允许您指示 Tina 的内容 API 查找哪种内容类型、如何标记等!
在查看当前项目之前,让我们讨论一下内容的结构。我们的架构可以分为三个概念:collections、fields 和 references。每个都有其角色:
Collections
架构中的顶级键是一个 collections 数组,一个 collection 告知 API 在哪里 保存内容。在我们的指南中,我们将有一个 posts 集合,但您也可以有一个 author 和 pages 集合,例如。
Fields
字段指示内容 API 预期的类型,例如 text,以及可查询的名称和要显示给您的内容团队的名称。字段是集合的子对象数组。我们使用它来从 Markdown 或 JSON 文件中检索内容,这些字段应映射到您的 frontmatter,我们还使用它来创建用于编辑的 UI 元素。
fields: [{type: "string",label: "Title",name: "title"},{type: "string",label: "Blog Post Body",name: "body",isBody: true,},]
References
这是一个重要的概念,当您 引用 另一个集合时,您实际上是在说:“这个文档 属于 那个文档”。使用引用的一个很好的例子是 author,因为每个帖子都有一个作者,您可以有多个作者,但您需要将特定的作者引用到帖子。
{"label": "Author","name": "author","type": "reference","collections": ["author"] // 指向名为 "author" 的集合}
在我们继续之前,您可以在我们的文档中阅读更多关于内容建模的信息
创建您的内容架构
从另一篇博客文章提供的博客中包含四个示例博客帖子,您将使用这些帖子在架构中塑造您的内容。您可以在 posts 目录中的任何博客帖子中找到,让我们看看 bali.md 的 front matter。
---author: Siddhartha Mukherjeedate: '2019-07-10T07:00:00.000Z'hero_image: /alfons-taekema-bali.jpgtitle: 'Bali —body, mind & soul'---术语 **bristlecone pine** 涵盖了三种 ...
如您所见,您有一些字段希望能够编辑,以及博客帖子的正文。
对架构进行更改
打开位于 /.tina/schema.ts 的 Tina schema.ts 文件。首先在我们提供的对象下方,您需要用您想要的内容替换当前集合:
{label: "Blog Posts",name: "post",- path: "content/posts"+ path: 'posts',fields: [{type: "string",label: "Title",name: "title"},{type: "string",label: "Blog Post Body",name: "body",isBody: true,},]}
到目前为止,您只替换了一行,即将 path 更新为博客内容的正确位置。
现在您需要处理每个帖子 frontmatter 的字段,下面是完成的文件:
import { defineSchema } from 'tinacms';export default defineSchema({collections: [{label: 'Blog Posts',name: 'post',path: '_posts',fields: [{type: 'string',label: 'Title',name: 'title',},{type: 'string',label: 'Author',name: 'author',},{type: 'datetime',label: 'Date',name: 'date',},{type: 'string',label: 'Image',name: 'hero_image',},{type: 'string',label: 'Body',name: 'body',isBody: true,},],},],});
您可能会注意到一些事情。首先,您有一个名为 datetime 的 type,它通过提供一个日期选择器供您使用,并将格式化日期和时间。
其次,有一个名为 body 的 string 字段,isBody 设置为 true。通过将 isBody 设置为 true,您声明此字段负责 Markdown 文件的主要 body。只能有一个字段具有 isBody: true 属性。
下一步
您的 Markdown 文件现在由一个定义良好的架构支持,这为我们使用 GraphQL 查询文件内容铺平了道路。您会注意到,当在 Next.js 博客入门模板中导航时,什么都没有改变,这是因为您需要更新入门模板以使用您的 GraphQL 层,而不是直接访问 Markdown 文件。在下一节中,您将处理将前端转换为使用 TinaCMS。
目前,Next 博客入门模板从文件系统中获取内容。但由于 Tina 带有一个文件系统之上的 GraphQL API,您将改为查询它。使用 GraphQL API 将允许您使用 TinaCMS 的强大功能,您将能够检索内容,还可以直接编辑和保存内容。
创建 getStaticPaths 查询
getStaticPaths 查询需要知道所有 Markdown 文件的位置,使用您当前的架构,您可以使用 postConnection,它将提供 posts 文件夹中所有帖子的列表。确保您的本地服务器正在运行,并导航到 http://localhost:4001/altair 并选择 Docs 按钮。Docs 按钮使您能够查看所有可能的查询和返回的变量:
因此,基于 postConnection,您将希望查询 sys,即文件系统,并检索 filename,这将返回所有不带扩展名的文件名。
query {postConnection {edges {node {_sys {filename}}}}}
如果您在 GraphQL 客户端中运行此查询,您将看到以下返回:
{"data": {"postConnection": {"edges": [{"node": {"_sys": {"filename": "bali"}}},{"node": {"_sys": { "filename": "iceland" }}},{"node": {"_sys": { "filename": "joshua-tree" }}},{"node": {"_sys": { "filename": "mauritius" }}}]}}}
将此查询添加到您的博客
上面的查询可以用来创建您的动态路径,这发生在 [slug].js 文件中。当您打开文件时,您将看到一个名为 getStaticPaths 的函数位于文件底部。
export async function getStaticPaths() {....
删除此函数中的所有代码,您可以更新它以使用您自己的代码。第一步是在文件顶部添加一个导入,以便能够与您的 graphql 层进行交互。在那里,您可以删除 glob,因为您将不再需要它。
//其他导入.....+ import { staticRequest } from "tinacms";- const glob = require('glob')
“staticRequest 是做什么的?”
它只是一个帮助函数,向您本地运行的 GraphQL 服务器提供查询,该服务器在端口 4001 上启动。您也可以轻松地使用 fetch 或您选择的 http 客户端。
在 getStaticPaths 函数内部,您可以构建对我们的内容 API 的请求。在发出请求时,Tina 期望传递查询或变更以及变量,这是一个示例:
staticRequest({query: '...', // 我们的查询variables: {...}, // 查询使用的任何变量}),
您可以使用之前的 postConnection 查询来构建您的动态路由:
export async function getStaticPaths() {const postsListData = await staticRequest({query: `query {postConnection {edges {node {_sys {filename}}}}}`,variables: {},});return {paths: postsListData.postConnection.edges.map((edge) => ({params: { slug: edge.node._sys.filename },})),fallback: false,};}
getStaticPaths 的快速分解
getStaticPaths 代码获取您创建的 graphql 查询,因为它不需要任何 variables,您可以发送一个空对象。在返回功能中,您遍历 postsListData.getPostList 中的每个项目,并为每个项目创建一个 slug。
您现在需要创建另一个查询,此查询将填充所有数据,并使您能够使所有博客帖子可编辑。
继续测试您的博客帖子是否仍然可读,例如导航到 http://localhost:3000/blog/bali
创建 getStaticProps 查询
getStaticProps 查询将向博客提供所有内容,这就是它当前的工作方式。当您使用 GraphQL API 时,Tina 将同时提供内容,并使内容团队能够直接在浏览器中编辑它。
您需要从您的内容 API 中查询以下项目:
- author
- date
- hero_image
- title
创建您的查询
使用您的本地 graphql 客户端,您可以使用博客帖子的路径查询 post,下面是您需要填写的骨架。
query BlogPostQuery($relativePath: String!) {post(relativePath: $relativePath) {# 这是您希望从帖子中检索的数据。}}
如果您以前没有使用过 graphql,您会注意到一个奇怪的$relativePath后跟String!。这是一个变量,String! 表示它必须是一个字符串并且是必需的。
您现在可以填写您需要查询的相关字段。在数据对象中添加字段 author、date、hero_image、title。您还希望检索博客帖子的正文,以便可以添加新内容。您应该有一个如下所示的查询:
query BlogPostQuery($relativePath: String!) {getPostDocument(relativePath: $relativePath) {titledatehero_imageauthorbody}}
如果您想测试一下,可以在底部的变量部分添加以下内容{"relativePath": "bali.md"}
使用上下文编辑
您需要在博客上设置上下文编辑,以便可以使用我们的侧边栏编辑内容,类似于开头的演示。首先,您需要在页面顶部导入 useTina 钩子。
//... 所有导入import { useTina } from 'tinacms/dist/edit-state';
什么是useTina?
useTina是一个钩子,可用于使 Tina 内容的一部分在上下文中可编辑。它是代码分割的,因此在生产环境中,此钩子将简单地传递其数据值。在编辑模式中,它在侧边栏中注册一个可编辑的表单,并在用户输入时上下文更新其值。
您现在可以将您创建的查询用作变量,此变量将在您的 getStaticProps 和 useTina 钩子中使用。
const query = `query BlogPostQuery($relativePath: String!) {post(relativePath: $relativePath) {titledatehero_imageauthorbody}}`;
替换您的 getStaticProps
要替换您的 getStaticProps,您将以类似于在 getStaticPaths 代码中使用的方式使用 staticRequest。
首先要做的是删除您不再需要的所有代码,包括 content 和 data 变量以及 markdownBody、frontmatter 从您的 props 中。
export async function getStaticProps({ ...ctx }) {const { slug } = ctx.params- const content = await import(`../../posts/${slug}.md`)const config = await import(`../../data/config.json`)- const data = matter(content.default)return {props: {siteTitle: config.title,- frontmatter: data.data,- markdownBody: data.content,},}}
现在您已从代码中删除了这些内容,您可以使用我们的 staticRequest 来检索数据。唯一的区别是这次您实际上需要一个名为 relativePath 的变量,它是 slug。您还需要将变量作为 prop 发送,以便可以在我们的 useTina 钩子中使用它。
export async function getStaticProps({ ...ctx }) {const { slug } = ctx.paramsconst config = await import(`../../data/config.json`)const data = await staticRequest({query,variables = {relativePath : slug,},})return {props: {data,variables,siteTitle: config.title,},}}
更新客户端以使用 useTina
现在您只从 getStaticProps 返回两个 props,您需要更新客户端代码以使用它们。删除解构的元素并将 props 传递给您的客户端。
export default function BlogTemplate(props) {
现在您可以使用 useTina 钩子来处理可视化编辑。useTina 钩子需要查询、变量和数据。您可以从您的 props 中传递这些。
const { data } = useTina({query,variables: props.variables,data: props.data,})
这意味着您现在可以使用 Tina 编辑您的内容,但在此之前,您需要更新所有元素以使用您的新 Tina 驱动的数据。
- if (!frontmatter) return <></>return (- <Layout siteTitle={siteTitle}>+ <Layout siteTitle={props.siteTitle}><article className={styles.blog}><figure className={styles.blog__hero}><Imagewidth="1920"height="1080"- src={frontmatter.hero_image}+ src={data.post.hero_image}- alt={`blog_hero_${frontmatter.title}`}+ alt={`blog_hero_${data.post.title}`}/></figure><div className={styles.blog__info}>- <h1>{frontmatter.title}</h1>+ <h1>{data.post.title}</h1>- <h3>{reformatDate(frontmatter.date)}</h3>+ <h3>{reformatDate(data.post.date)}</h3></div><div className={styles.blog__body}>- <ReactMarkdown children={markdownBody} />+ <ReactMarkdown children={data.post.body} /></div>- <h2 className={styles.blog__footer}>Written By: {frontmatter.author}</h2>+ <h2 className={styles.blog__footer}>Written By: {data.post.author}</h2></article></Layout>)}
测试和编辑内容 ✨
如果一切顺利,您的博客帖子现在可以通过 Tina 编辑了。让我们看看它的实际效果!
通过运行 yarn dev 启动开发服务器,并在浏览器中打开一个博客帖子。继续进行编辑,然后在文本编辑器中检查源文件。如果您将浏览器和代码编辑器并排打开,您应该能够实时观察到更改在两个地方的反映!
不过您遇到了一个问题,您的正文是一个不支持 Markdown 的小输入框!您应该修复这个问题。
添加 Markdown 支持
要添加 Markdown 支持,您需要做两件事。
- 告诉 Tina 如何使用不同的组件。
- 动态加载 Markdown 组件。
更新 Tina 架构
打开位于 .tina 文件夹中的 schema.ts。Tina 的一个优点是您可以扩展 UI 字段以满足您的确切需求,为此您可以使用 ui 对象并告诉 Tina 您想使用的组件。
ui: {component: COMPONENT_NAME;}
您希望使用 Markdown 组件,因此您可以覆盖您的正文,它应该如下所示:
{type: 'string',label: 'Body',name: 'body',isBody: true,ui: {component: 'markdown'}},
更新 _app.js
在打开您的 _app.js 文件之前,您需要从 Tina 安装 Markdown 插件。
yarn add react-tinacms-editor
打开您的 _app.js 文件,这是您将使用 TinaCMS 组件的 cmsCallback prop 的地方,它允许您扩展默认功能,添加插件,处理文档创建等。
cmsCallback={cms => {
在这里,您传递了 cms,现在您可以导入我们安装的组件以添加