使用Gatsby创建Markdown草稿
编辑工作流的核心功能之一是为作者和编辑提供一个安全的空间,以便在这些正在处理的帖子未发布到生产环境时创建和迭代内容——草稿模式。
本文将概述如何在使用TinaCMS的Gatsby网站中为Markdown文件添加草稿状态。根据环境和文件的草稿状态,它们将被选择性地“发布”或不发布。在开发中,我们将“发布”所有文件,以便我们可以查看和编辑草稿和已完成的帖子;而在生产中,我们将在我们的graphQL查询中过滤掉草稿帖子。
代码示例基于gatsby-starter-tinacms。在阅读过程中可以随时参考。
步骤1:向MarkdownRemark节点添加已发布字段
首先,我们需要创建一种方法来告诉Gatsby根据环境选择要包含(或不包含)在构建过程中的文件。为此,我们将向每个MarkdownRemark节点添加一个published字段。published字段是文件被包含在构建过程中的开关。在开发模式下,开关是完全打开的,所有帖子,无论其草稿状态如何,都会被“发布”或通过构建过程。在生产模式下,开关会过滤掉任何处于草稿状态的内容。因此,可以将published视为includedInBuild的一个误称。
我们需要修改的第一个文件是gatsby-node.js文件,通常位于站点的根目录。这是一个特殊的gatsby文件,我们可以在其中访问所有Gatsby的Node-API,或访问处理Gatsby站点中所有数据的GraphQL层的入口点。我们将使用的API称为setFieldsOnGraphQLNodeType:
const { GraphQLBoolean } = require('gatsby/graphql')exports.setFieldsOnGraphQLNodeType = ({ type }) => {// 如果节点是markdown文件,添加`published`字段if ('MarkdownRemark' === type.name) {return {published: {type: GraphQLBoolean,resolve: ({ frontmatter }) => {/*在开发中,`published`总是为true因此草稿和完成的帖子都会被构建*/if (process.env.NODE_ENV !== 'production') {return true}/*返回`draft`值的相反值,即如果draft = true : published = false*/return !frontmatter.draft},},}}return {}}
步骤2:仅创建已发布的页面
在gatsby-node.js文件中,我们需要防止处于草稿状态的文件被Gatsby创建为页面。我们需要查询所有MarkdownRemark文件,特别是带有published字段的数据,以便我们仅在它们被published或设置为包含在构建中时创建页面。
让我们遍历所有帖子,仅为published内容调用createPage。此示例代码使用createPages API,这是您在Gatsby中操作或处理页面创建的地方。
exports.createPages = async ({ graphql, actions, reporter }) => {const { createPage } = actions// 查询用于创建页面的markdown节点。const result = await graphql(`{allMarkdownRemark(sort: { fields: [frontmatter___date], order: DESC } limit: 1000) {edges {node {publishedfields {slug}frontmatter {title}}}}}`)// 处理错误if (result.errors) {reporter.panicOnBuild(`运行GraphQL查询时出错。`)return}// 为每个markdown文件创建页面。const blogPostTemplate = path.resolve(`src/templates/blog-post.js`)result.data.allMarkdownRemark.edges.forEach(({ node }) => {// 如果未发布,则返回,以防止页面被创建if (!node.published) return// 否则,创建`published`页面createPage({path: node.fields.slug,component: blogPostTemplate,context: {slug: node.fields.slug},})}}
步骤3:在查询级别过滤未发布的页面
现在我们有了控制帖子是否包含在构建中的已发布字段,我们需要调整模板和索引列表文件中的查询,以便我们仅查询published数据。
转到渲染所有帖子“列表”的组件或页面文件——这可能是一个简单博客的索引文件,或者是一个更复杂网站的列表页面文件。在该文件中,让我们为allMarkdownRemark查询添加一个过滤参数:
src/pages/index.js
export const pageQuery = graphql`query {// 仅查询已发布的markdown文件allMarkdownRemark(filter: { published: { eq: true } }, sort: { fields: [frontmatter___date], order: DESC }) {edges {node {excerptfields {slug}frontmatter {date(formatString: "MMMM DD, YYYY")titledescription}}}}}`
博客文章模板中的查询也是如此。
src/templates/blog-post.js
export const pageQuery = graphql`query BlogPostBySlug($slug: String!) {// 未发布的页面将404markdownRemark(published: { eq: true }, fields: { slug: { eq: $slug } }) {// ...}}`
现在,我们处理任何博客文章数据的模板和组件将根据构建环境有条件地处理published内容。
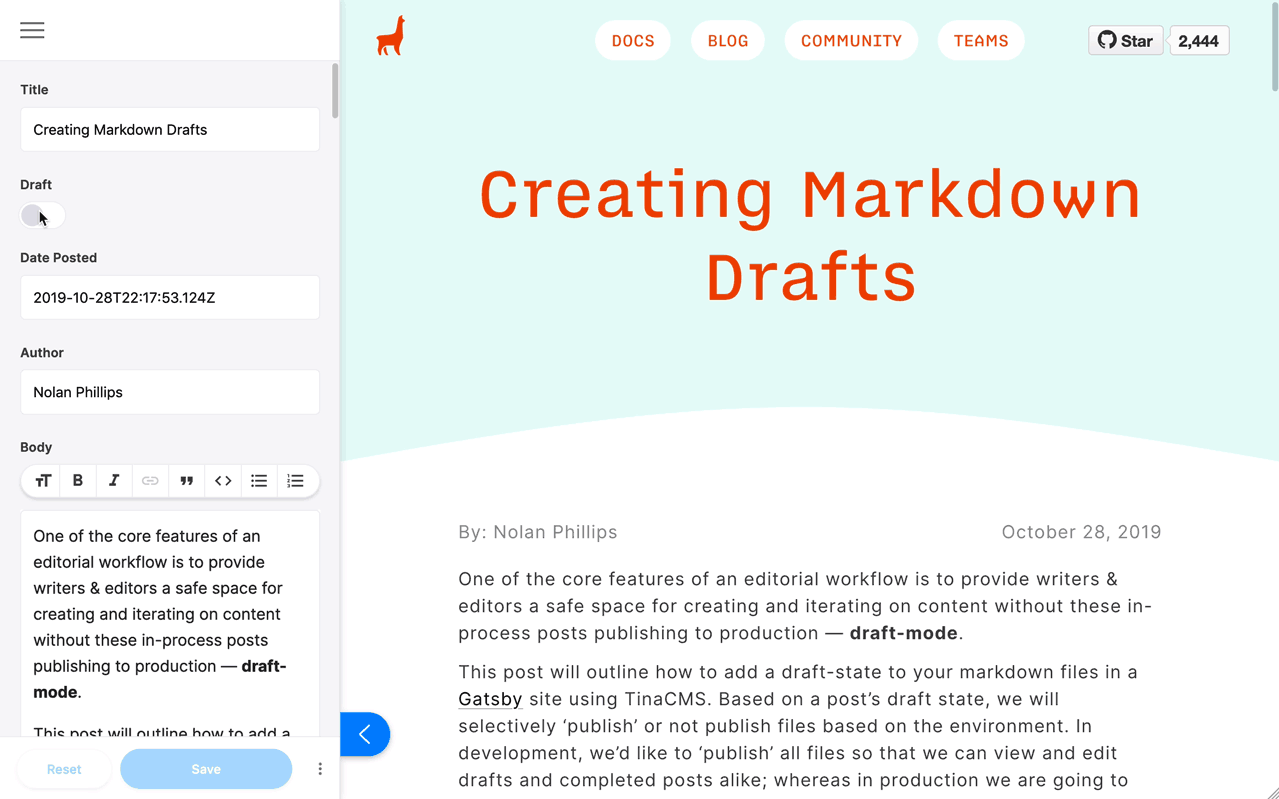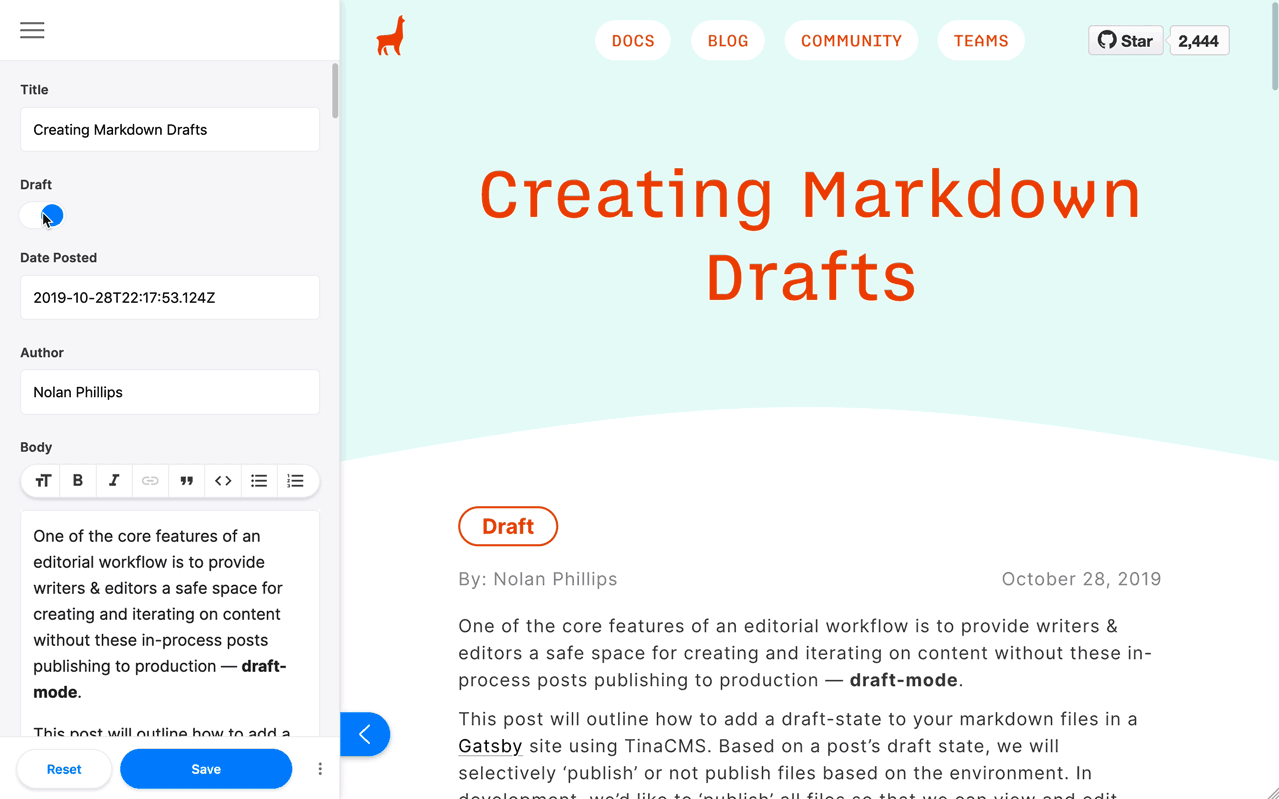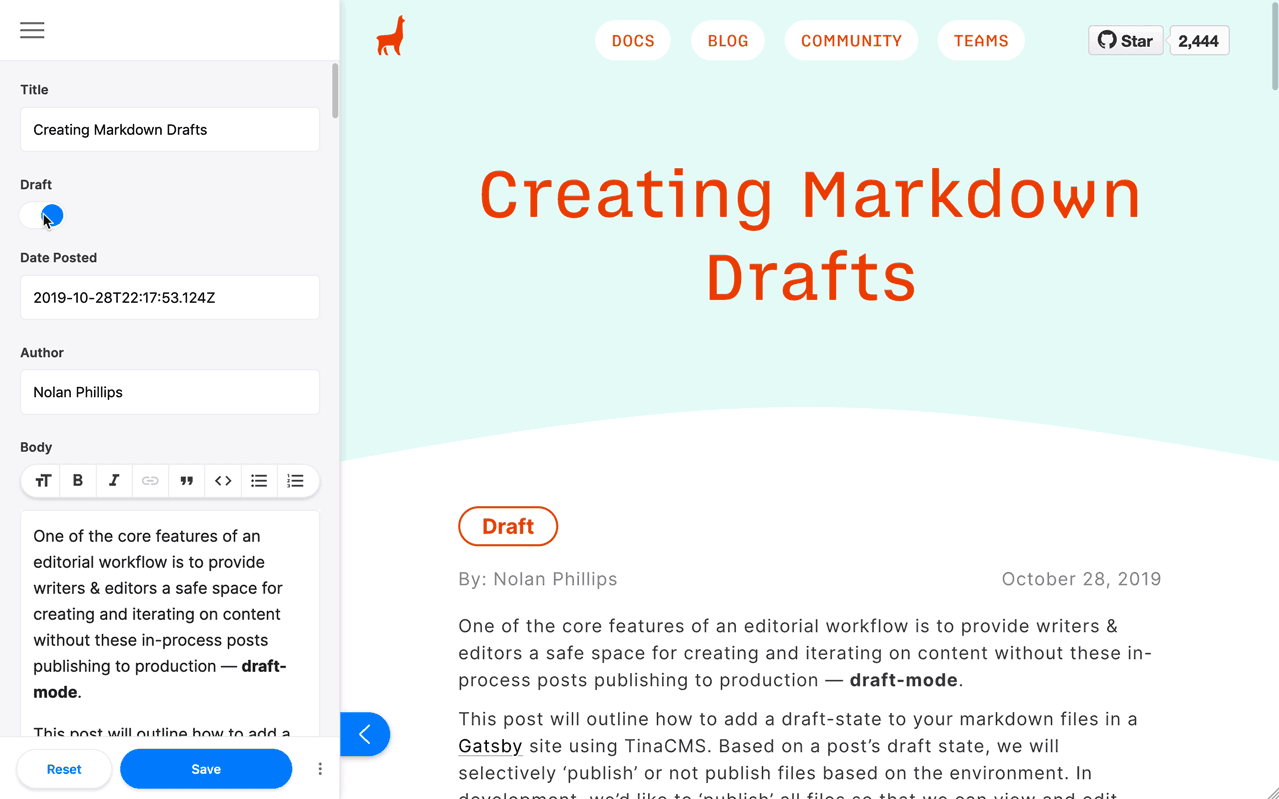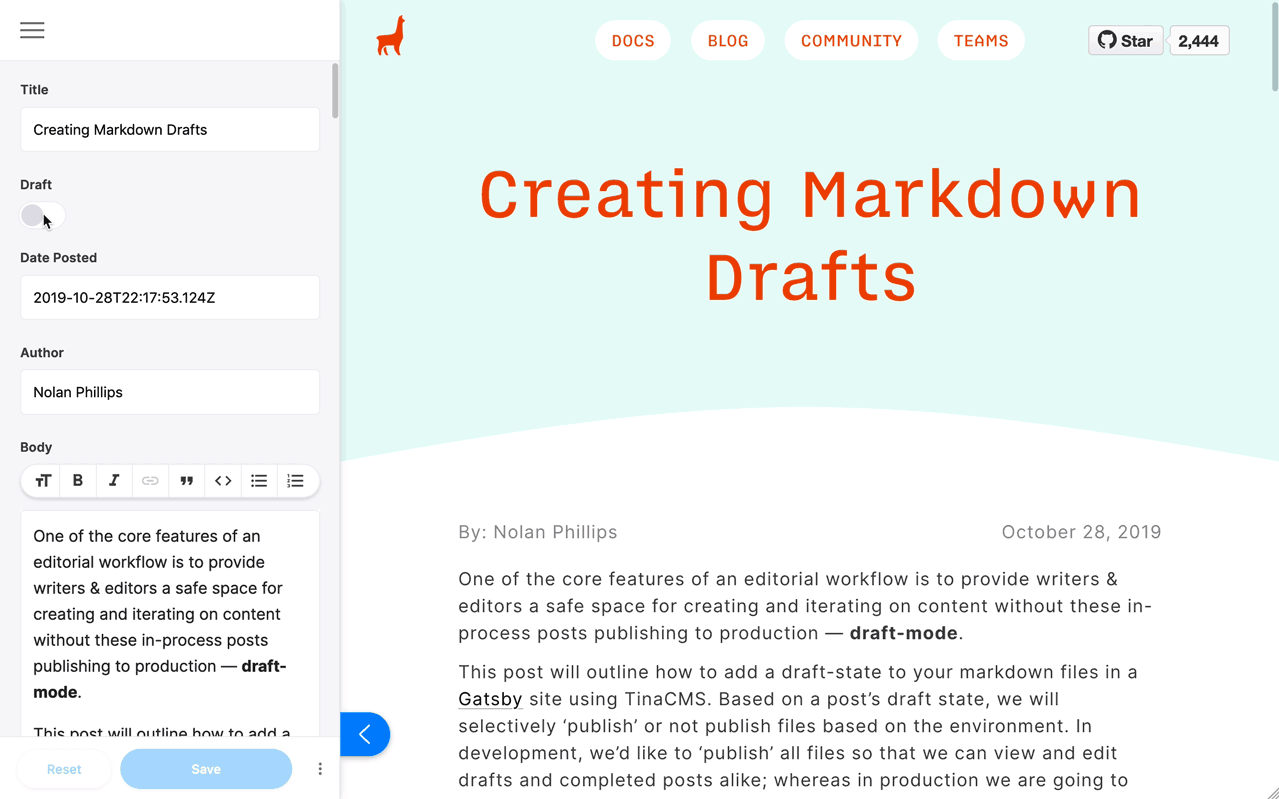
步骤4:在开发中添加“草稿”指示器
既然您已经在您的blog-post.js模板文件中并添加了过滤参数,我们现在需要将‘draft’字段添加到我们的查询中,以便我们可以在组件中有条件地渲染一些帖子状态的指示。调整此查询后,您可能需要重新启动Gatsby开发服务器。
将draft添加到您的blog-post.js查询中:
export const pageQuery = graphql`query BlogPostBySlug($slug: String!) {markdownRemark(published: { eq: true }, fields: { slug: { eq: $slug } }) {frontmatter {titledate(formatString: "MMMM DD, YYYY")description// 新字段draft}}}`
您可以通过多种方式将‘draft’指示器状态合并到您的组件中。一个方法是根据frontmatter.draft的值有条件地渲染草稿状态而不是日期,如下例所示:
<pstyle={{...scale(-1 / 5),display: `block`,marginBottom: rhythm(1),}}>{post.frontmatter.draft ? <DraftIndicator /> : post.frontmatter.date}</p>
步骤5:将草稿切换添加到您的表单中
最后,让我们将此草稿切换字段添加到表单中,我们在TinaCMS中编辑博客文章。只需将此字段添加到每个页面的表单定义中。
{name: "frontmatter.draft",component: "toggle",label: "Draft",},
注意:
Tina仅会在文件被编辑后添加draft frontmatter值。如果文件上未设置draft frontmatter值,它将为null(假值),并将在所有环境中发布。
就这样!
我们成功地为一个简单的博客添加了“草稿模式”。现在,根据您的网站配置可能会略有不同,但可以随时参考TinaCMS-site仓库,特别是博客模板,以查看此功能在更复杂网站上的实际应用。