Tina + Next: Part II
This blog is a part of a series exploring the use of Next.js + Tina. In Part I, you learned how to create a simple markdown-based blog with Next. In this post you’ll add content editing capacity by configuring the site with TinaCMS.
Next.js Recap ▲
Next.js is a React “meta-framework” (a framework built on a framework) for developing web applications, built by the team at Vercel. Read Part I to get familiar with Next.js basics.
Tina Overview 🦙
Tina is a Git-backed headless content management system that enables developers and content creators to collaborate seamlessly. With Tina, developers can create a custom visual editing experience that is perfectly tailored to their site.
The best way to get a feel for how Tina works is to use it. We hope that by the end of this tutorial, you’ll not only learn how to use Tina, but also how Tina rethinks the way a CMS should work.
Let’s Get Started
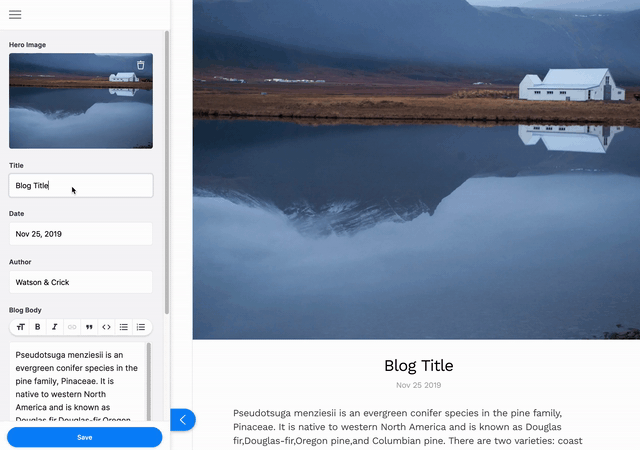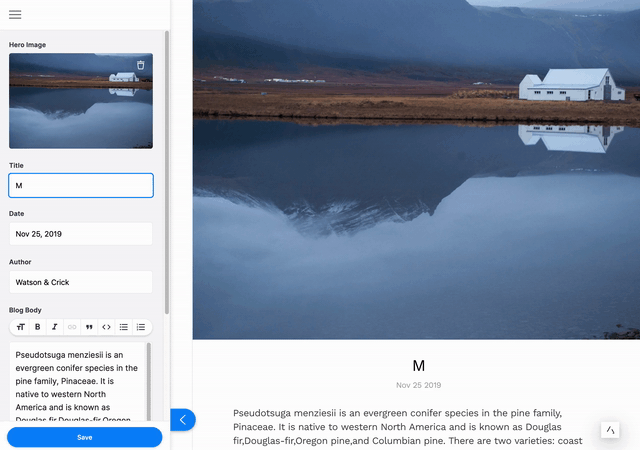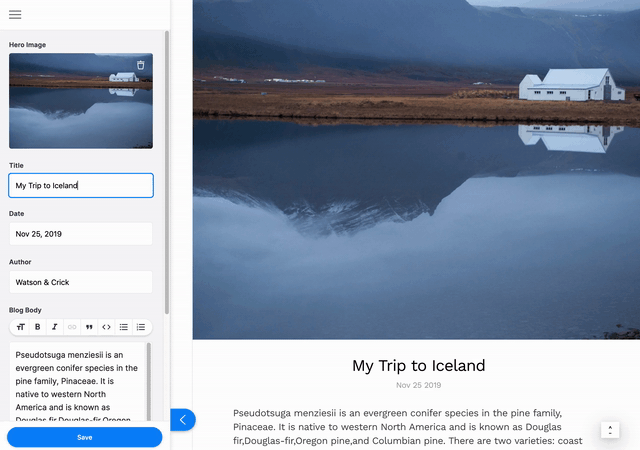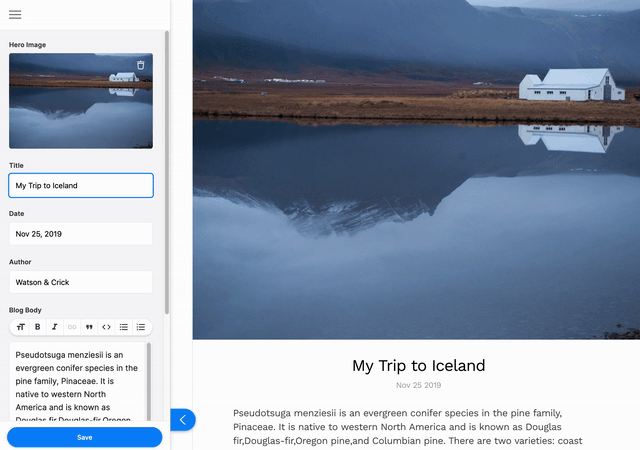
This tutorial will show you how to install and configure Tina for editing content on a simple markdown-based blog that was created in last week’s post. If you want to dig into how the base blog was made, read Part I of this series.
Jump ahead and check out the Tina documentation here
Set up Locally 🏡
Feel free to follow along and fit these guidelines to your own site or blog, or you can use the starter we created in the previous tutorial. In your terminal, navigate to where you would like this blog to live, then run:
# clone the repo$ git clone https://github.com/tinalabs/brevifolia-next-2022 next-tina-blog# navigate to the directory$ cd next-tina-blog# install dependencies & init Tina$ yarn install$ npx @tinacms/cli@latest init$ do you want us to override your _app.js? Yes
The npx @tinacms/cli@latest init command does a few things in your Next.js application:
- Install all required dependencies for Tina
- Define a basic schema that is easily extendable, in the .tina directory
- Wrap your next.js application with Tina so that any page can be easily edited.
- Create example content in the demo directory.
- Edit the package.json to add scripts to launch tina (dev, build, start)
A quick test
Now that you have a basic Tina setup you can launch your application using the following command:
yarn dev
Once you have launched the application you have a couple of new URLS:
http://localhost:3000/demo/blog/HelloWorldhttp://localhost:4001/altair/
The first URL brings you to a demo of TinaCMS, it will show you the power of Tina and also give you some informational links to check out. If you navigate to http://localhost:3000/demo/blog/HelloWorld, you won't be able to edit right away. First, you need to enter edit mode. To enter edit mode, navigate to http://localhost:3000/admin, select login. Then navigate back to http://localhost:3000/demo/blog/HelloWorld. Selecting the pencil in the top left allows you to edit the title and the body of the page right in the frontend. When you hit save, that will save your changes to the Markdown file.
Want to see your changes? Open up the file located at/content/posts/HelloWorld.mdand the changes you've made will be there! This works by using our Content API which will go into greater depth during this guide.
The second URL http://localhost:4001/altair/ will launch a graphQL client that will allow you to interact and create queries which will be in this guide.
Defining the shape of our content
One key element of Tina is defining a schema that allows you to shape and interact with the content on the page. Opening up the project, you will see a folder called .tina which contains a schema.ts file. This file allows you to instruct Tina's Content API which content type to look for, how it should be labeled, and much more!
Before you look at your current project, let's discuss how the content is shaped. Our schema can be broken down into three concepts: collections, fields and references. Each one of them has its role:
Collections
The top-level key in the schema is an array of collections, a collection informs the API about where to save content. In our guide we are going to have a posts collection but you also could have an author and pages collections, for example.
Fields
Fields instruct the Content API of the type expected for example, text, as well as the queryable name and the name to display to your content team. Fields are an array of objects that are a child of collections. We use this to retrieve the content from the Markdown or JSON files, these fields should map to your frontmatter , and we also use this to create the UI elements for editing.
fields: [{type: "string",label: "Title",name: "title"},{type: "string",label: "Blog Post Body",name: "body",isBody: true,},]
References
This is an important concept, when you reference another collection, you're effectively saying: "this document belongs to that document". A great example of using a reference is author as each post would have an author and you could have multiple authors, but you need to reference a particular author to the post.
{"label": "Author","name": "author","type": "reference","collections": ["author"] // points to a collection with the name "author"}
Before we move on you can read more about content modeling in our documentation
Creating your content Schema
The blog provided from another blog post comes with four example blog posts that you are going to use to shape your content in your schema. You can find on any of the blog posts in the posts directory, let us look at the front matter of the bali.md.
---author: Siddhartha Mukherjeedate: '2019-07-10T07:00:00.000Z'hero_image: /alfons-taekema-bali.jpgtitle: 'Bali —body, mind & soul'---The term **bristlecone pine** covers three ...
As you can see, you have a few fields that you want to be able to edit as well as the body of the blog post.
Making changes to the Schema
Open up the Tina schema.ts file located at /.tina/schema.ts To begin with underneath the object we provided, you need to replace the current collection with the content you want:
{label: "Blog Posts",name: "post",- path: "content/posts"+ path: 'posts',fields: [{type: "string",label: "Title",name: "title"},{type: "string",label: "Blog Post Body",name: "body",isBody: true,},]}
You have only replaced a single line so far, which is to update the path to the correct location of the Blog content.
Now you need to handle each field for your posts frontmatter, below is the finished file:
import { defineSchema } from 'tinacms';export default defineSchema({collections: [{label: 'Blog Posts',name: 'post',path: '_posts',fields: [{type: 'string',label: 'Title',name: 'title',},{type: 'string',label: 'Author',name: 'author',},{type: 'datetime',label: 'Date',name: 'date',},{type: 'string',label: 'Image',name: 'hero_image',},{type: 'string',label: 'Body',name: 'body',isBody: true,},],},],});
There are a couple of things you might notice. First, you have a type called datetime, this works by providing a date picker for you to use, and will format the date and time.
Second, there's a string field called body with isBody set to true. By setting isBody to true you're stating that this field is responsible for the main body of the markdown file. There can only be one field with the isBody: true property.
Next steps
Your Markdown files are now backed by a well-defined schema, this paves the way for us to query file content with GraphQL. You will notice that nothing has changed when navigating around the Next.js blog starter, this is because you need to update the starter to use your GraphQL layer instead of directly accessing the Markdown files. In the next section you will handle converting the frontend to use TinaCMS.
Currently, the Next Blog Starter grabs content from the file system. But since Tina comes with a GraphQL API on top of the filesystem, you’re going to query that instead. Using the GraphQL API will allow you to use the power of TinaCMS, you will be able to retrieve the content and also edit and save the content directly.
Creating the getStaticPaths query
The getStaticPaths query is going to need to know where all of your markdown files are located, with your current schema you have the option to use postConnection which will provide a list of all posts in your posts folder. Make sure your local server is running and navigate to http://localhost:4001/altair and select the Docs button. The Docs button gives you the ability to see all the queries possible and the variables returned:
So based upon the postConnection you will want to query the sys which is the filesystem and retrieve the filename, which will return all the filenames without the extension.
query {postConnection {edges {node {_sys {filename}}}}}
If you run this query in the GraphQL client you will see the following returned:
{"data": {"postConnection": {"edges": [{"node": {"_sys": {"filename": "bali"}}},{"node": {"_sys": { "filename": "iceland" }}},{"node": {"_sys": { "filename": "joshua-tree" }}},{"node": {"_sys": { "filename": "mauritius" }}}]}}}
Adding this query to your Blog.
The query above can be used to create your dynamic paths, this happens inside of the [slug].js file. When you open the file you will see a function called getStaticPaths at the bottom of the file.
export async function getStaticPaths() {....
Remove all the code inside of this function and you can update it to use your own code. The first step is to add an import to the top of the file to be able interact with your graphql layer. While you are there you can remove glob, as you will no longer need it.
//other imports.....+ import { staticRequest } from "tinacms";- const glob = require('glob')
"What does staticRequest do?"
It's just a helper function which supplies a query to your locally-running GraphQL server, which is started on port 4001. You can just as easily use fetch or an http client of your choice.
Inside of the getStaticPaths function you can construct your request to our content-api. When making a request Tina expects a query or mutation and then variables to be passed to the query, here is an example:
staticRequest({query: '...', // our queryvariables: {...}, // any variables used by our query}),
You can use the postConnection query from earlier to build your dynamic routes:
export async function getStaticPaths() {const postsListData = await staticRequest({query: `query {postConnection {edges {node {_sys {filename}}}}}`,variables: {},});return {paths: postsListData.postConnection.edges.map((edge) => ({params: { slug: edge.node._sys.filename },})),fallback: false,};}
Quick break down of getStaticPaths
The getStaticPaths code takes the graphql query you created, because it does not require any variables you can send down an empty object. In the return functionality, you map through each item in the postsListData.getPostList and create a slug for each one.
You now need to create one more query, this query will fill in all the data and give you the ability to make all your blog posts editable.
Go ahead and test that your blog posts are still readable by navigating to one, for example http://localhost:3000/blog/bali
Creating the getStaticProps query
The getStaticProps query is going to deliver all the content to the blog, which is how it works currently. When you use the GraphQL API Tina will both deliver the content and give the content team the ability to edit it right in the browser.
You need to query the following items from your content api:
- author
- date
- hero_image
- title
Creating your Query
Using your local graphql client you can query the post using the path to the blog post in question, below is the skeleton of what you need to fill out.
query BlogPostQuery($relativePath: String!) {post(relativePath: $relativePath) {# this is data you want to retrieve from your posts.}}
If you haven't used graphql before, you will notice a strange$relativePathfollowed byString!. This is a variable and the String! means that it must be a string and is required.
You can now fill in the relevant fields you need to query. Inside the data object add in the fields author , date , hero_image, title. You also want to retrieve the body of your blog posts, so you can add new content. You should have a query that looks like the following:
query BlogPostQuery($relativePath: String!) {getPostDocument(relativePath: $relativePath) {titledatehero_imageauthorbody}}
If you would like to test this out, you can add the following to the variables section at the bottom{"relativePath": "bali.md"}
Using contextual-editing
You need to set up contextual-editing on your blog so that you can edit the content using our sidebar, similar to the demo at the beginning. First, you need to import useTina hook at the top of the page.
//... all your importsimport { useTina } from 'tinacms/dist/edit-state';
What isuseTina?
useTinais a hook that can be used to make a piece of Tina content contextually editable. It is code-split, so that in production, this hook will simply pass through its data value. In edit-mode, it registers an editable form in the sidebar, and contextually updates its value as the user types.
You can now use your query that you created as a variable, this variable will be used both in your getStaticProps and in your useTina hook.
const query = `query BlogPostQuery($relativePath: String!) {post(relativePath: $relativePath) {titledatehero_imageauthorbody}}`;
Replacing your getStaticProps
To replace your getStaticProps you will be using the staticRequest in a similar way to what you used in our getStaticPaths code.
The first thing to do is remove all the code you no longer need, this includes the content, and data variables and the markdownBody, frontmatter from your props.
export async function getStaticProps({ ...ctx }) {const { slug } = ctx.params- const content = await import(`../../posts/${slug}.md`)const config = await import(`../../data/config.json`)- const data = matter(content.default)return {props: {siteTitle: config.title,- frontmatter: data.data,- markdownBody: data.content,},}}
Now you have removed that from your code, you can use our staticRequest to retrieve the data. The only difference this time is you actually need a variable to pass along named relativePath, which is the slug. You will also need to send the variables along as a prop so you can use this in our useTina hook.
export async function getStaticProps({ ...ctx }) {const { slug } = ctx.paramsconst config = await import(`../../data/config.json`)const data = await staticRequest({query,variables = {relativePath : slug,},})return {props: {data,variables,siteTitle: config.title,},}}
Updating the client for useTina
Now that you are returning only two props from getStaticProps you need to update your client code to use them. Remove the destructured elements and pass in props to your client.
export default function BlogTemplate(props) {
Now you can use the useTina hook to handle visual editing. The useTina hook expects the query, variables and data. Which you can pass in from your props.
const { data } = useTina({query,variables: props.variables,data: props.data,})
This now means you have the ability to edit your content using Tina, but before you do that you need to update all of your elements to use your new Tina powered data.
- if (!frontmatter) return <></>return (- <Layout siteTitle={siteTitle}>+ <Layout siteTitle={props.siteTitle}><article className={styles.blog}><figure className={styles.blog__hero}><Imagewidth="1920"height="1080"- src={frontmatter.hero_image}+ src={data.post.hero_image}- alt={`blog_hero_${frontmatter.title}`}+ alt={`blog_hero_${data.post.title}`}/></figure><div className={styles.blog__info}>- <h1>{frontmatter.title}</h1>+ <h1>{data.post.title}</h1>- <h3>{reformatDate(frontmatter.date)}</h3>+ <h3>{reformatDate(data.post.date)}</h3></div><div className={styles.blog__body}>- <ReactMarkdown children={markdownBody} />+ <ReactMarkdown children={data.post.body} /></div>- <h2 className={styles.blog__footer}>Written By: {frontmatter.author}</h2>+ <h2 className={styles.blog__footer}>Written By: {data.post.author}</h2></article></Layout>)}
Test & Edit Content ✨
If all went well, your blog posts will now be editable by Tina. Let's see it in action!
Start up the dev server by running yarn dev, and open up a blog post in the browser. Go ahead and make edits, and then check the source file in a text editor. If you keep the browser and code editor open side-by-side, you should be able to watch the changes reflect in real time in both places!
You had a problem though, your body is a tiny input box that doesn't support Markdown! You should fix this.
Adding Markdown Support
To add markdown support you need to do two things.
- Tell Tina how to use a different component.
- Dynamically load the markdown component.
Update Tina Schema
Open up your schema.ts located in the .tina folder. The great thing about Tina is you can extend the UI field for your exact needs, to do this you use ui object and tell Tina the component you'd like to use.
ui: {component: COMPONENT_NAME;}
You want to use the markdown component so you can override your body and it should look like this:
{type: 'string',label: 'Body',name: 'body',isBody: true,ui: {component: 'markdown'}},
Updating _app.js
Before opening up your _app.js file, you need to install the markdown plugin from Tina.
yarn add react-tinacms-editor
Open up your _app.js file, this is where you are going to use the cmsCallback prop for the TinaCMS component which allows you to extend the default functionality, add plugins, handle document creation, and more
cmsCallback={cms => {
Here you are passing the cms and now you can import our component you installed to add to the plugins.
import('react-tinacms-editor').then((field) => {cms.plugins.add(field.MarkdownFieldPlugin);});
Your TinaCMS should now look like this:
<TinaCMSapiURL={apiURL}cmsCallback={cms => {import('react-tinacms-editor').then((field)=>{cms.plugins.add(field.MarkdownFieldPlugin)})}}>
Testing
Go ahead and launch your blog and you should be able to see a new markdown editor that allows you to pass in data. Well done! With some config and calling a few hooks, you can now edit all our blog posts with Tina.
Where can you keep up to date with Tina?
You know that you will want to be part of this creative, innovative, supportive community of developers (and even some editors and designers) who are experimenting and implementing Tina daily.
Tina Community Discord
Tina has a community Discord that is full of Jamstack lovers and Tina enthusiasts. When you join you will find a place:
- To get help with issues
- Find the latest Tina news and sneak previews
- Share your project with Tina community, and talk about your experience
- Chat about the Jamstack
Tina Twitter
Our Twitter account (@tinacms) announces the latest features, improvements, and sneak peeks to Tina. We would also be psyched if you tagged us in projects you have built.